Redis面试 - 数据类型和数据结构
Redis面试 - 数据类型和数据结构
1 Redis 有哪些数据类型?
- 5种基础数据类型,分别是:String、List、Set、Zset、Hash。
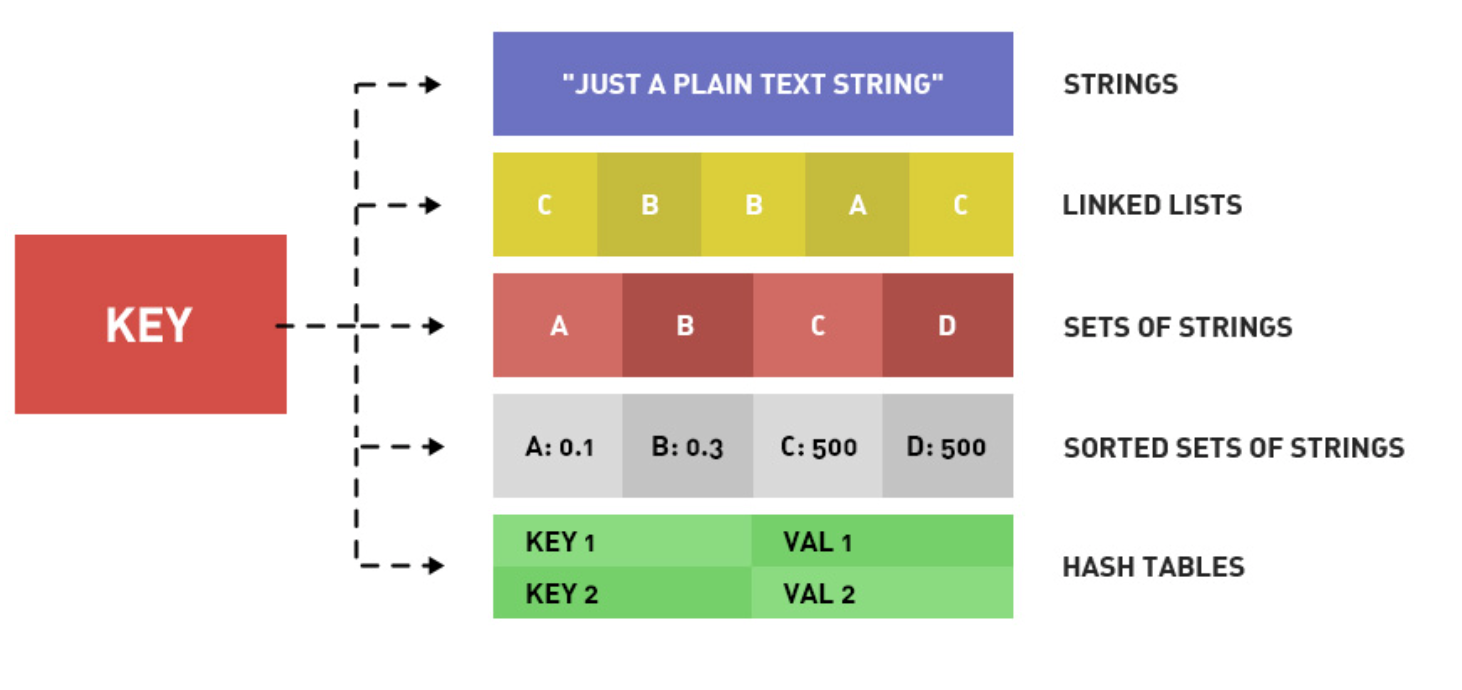
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作;对整数或浮点数进行自增或自减操作; |
| List列表 | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行push和pop操作,读取单个或多个元素;根据值查找或删除元素; |
| Set集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有看是否存在添加、获取、删除;还包含计算交集、并集、差集等 |
| Hash散列 | 包含键值对的无序散列表 | 包含方法有添加、获取、删除单个元素 |
| Zset有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射;元素的排列顺序由分数的大小决定;包含方法有添加、获取、删除单个元素以及根据分值范围或成员来获取元素 |
- 三种特殊的数据类型 分别是 HyperLogLogs(基数统计), Bitmaps (位图) 和 geospatial (地理位置)
2 谈谈Redis 的对象机制(redisObject)?
比如说, 集合类型就可以由字典和整数集合两种不同的数据结构实现, 但是, 当用户执行 ZADD 命令时, 他/她应该不必关心集合使用的是什么编码, 只要 Redis 能按照 ZADD 命令的指示, 将新元素添加到集合就可以了。
这说明, 操作数据类型的命令除了要对键的类型进行检查之外, 还需要根据数据类型的不同编码进行多态处理.
为了解决以上问题, Redis 构建了自己的类型系统, 这个系统的主要功能包括:
- redisObject 对象.
- 基于 redisObject 对象的类型检查.
- 基于 redisObject 对象的显式多态函数.
- 对 redisObject 进行分配、共享和销毁的机制.
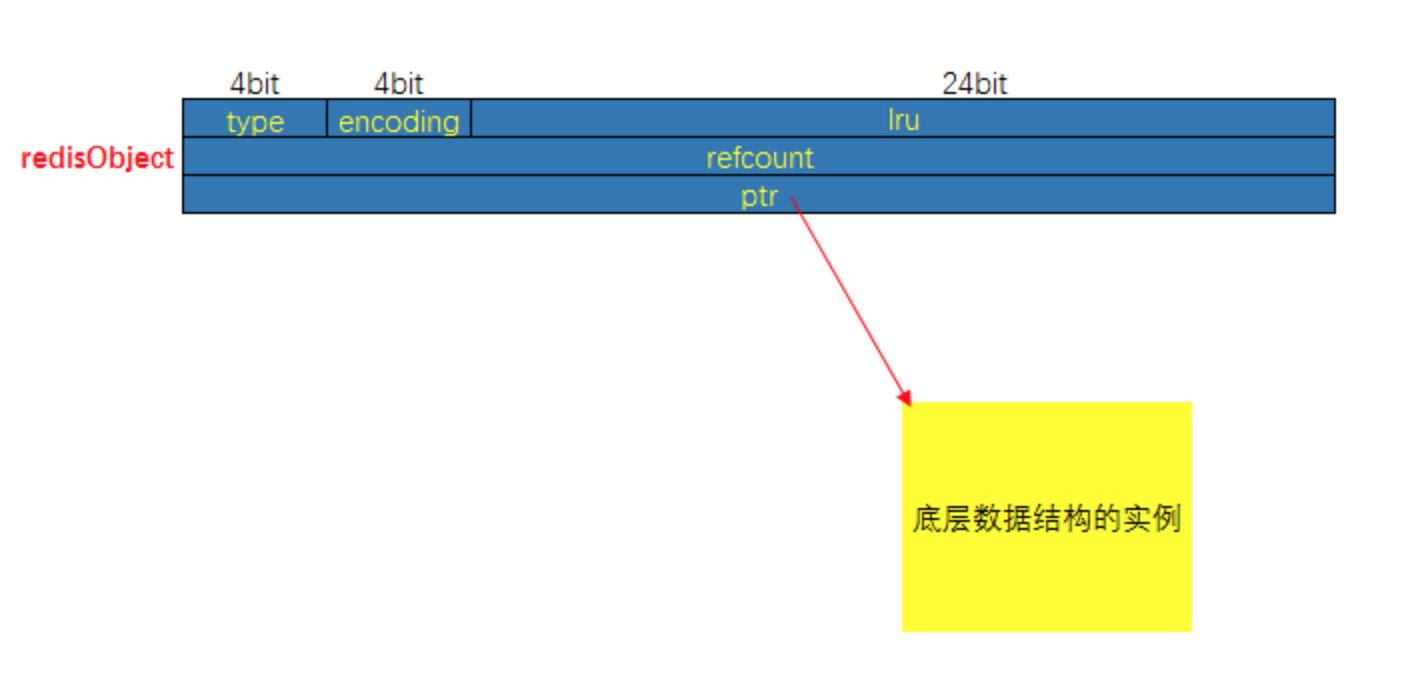
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码方式
unsigned encoding:4;
// LRU - 24位, 记录最末一次访问时间(相对于lru_clock); 或者 LFU(最少使用的数据:8位频率,16位访问时间)
unsigned lru:LRU_BITS; // LRU_BITS: 24
// 引用计数
int refcount;
// 指向底层数据结构实例
void *ptr;
} robj;
下图对应上面的结构
3 Redis 数据类型有哪些底层数据结构?
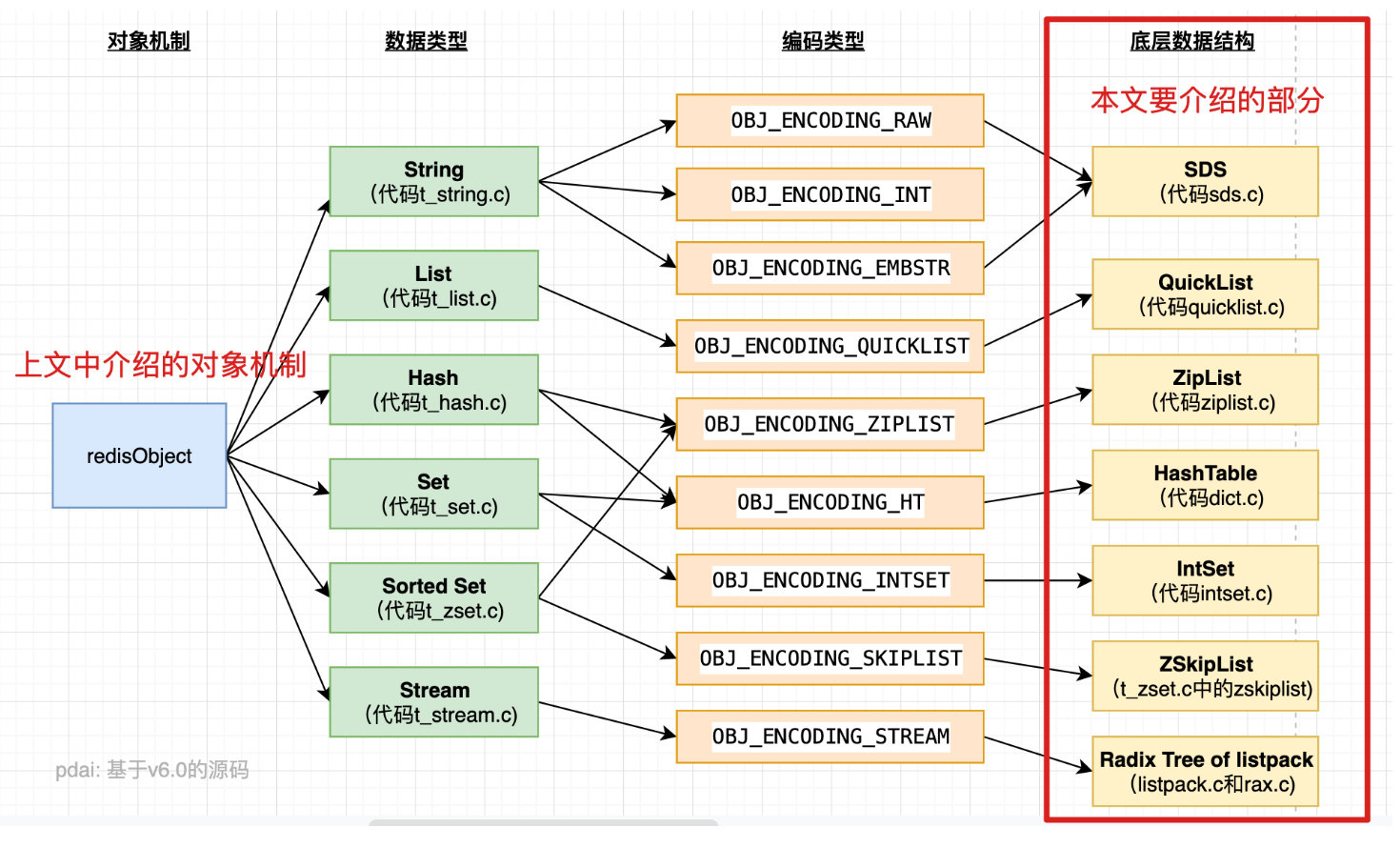
- 简单动态字符串 - sds
- 压缩列表 - ZipList
- 快表 - QuickList
- 字典/哈希表 - Dict
- 整数集 - IntSet
- 跳表 - ZSkipList
4 为什么要设计sds?
- 常数复杂度获取字符串长度
由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。通过 strlen key 命令可以获取 key 的字符串长度。
- 杜绝缓冲区溢出
我们知道在 C 语言中使用 strcat 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。
- 减少修改字符串的内存重新分配次数
C语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。
而对于SDS,由于len属性和alloc属性的存在,对于修改字符串SDS实现了空间预分配和惰性空间释放两种策略:
- 空间预分配:对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数。
- 惰性空间释放:对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用
alloc属性将这些字节的数量记录下来,等待后续使用。(当然SDS也提供了相应的API,当我们有需要时,也可以手动释放这些未使用的空间。)
- 二进制安全
因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而所有 SDS 的API 都是以处理二进制的方式来处理 buf 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。
- 兼容部分 C 字符串函数
虽然 SDS 是二进制安全的,但是一样遵从每个字符串都是以空字符串结尾的惯例,这样可以重用 C 语言库<string.h> 中的一部分函数。
5 Redis 一个字符串类型的值能存储最大容量是多少?
512M
6 为什么会设计Stream?
用过Redis做消息队列的都了解,基于Reids的消息队列实现有很多种,例如:
- PUB/SUB,订阅/发布模式
- 但是发布订阅模式是无法持久化的,如果出现网络断开、Redis 宕机等,消息就会被丢弃;
- 基于List LPUSH+BRPOP 或者 基于Sorted-Set 的实现
- 支持了持久化,但是不支持多播,分组消费等
消费组消费图
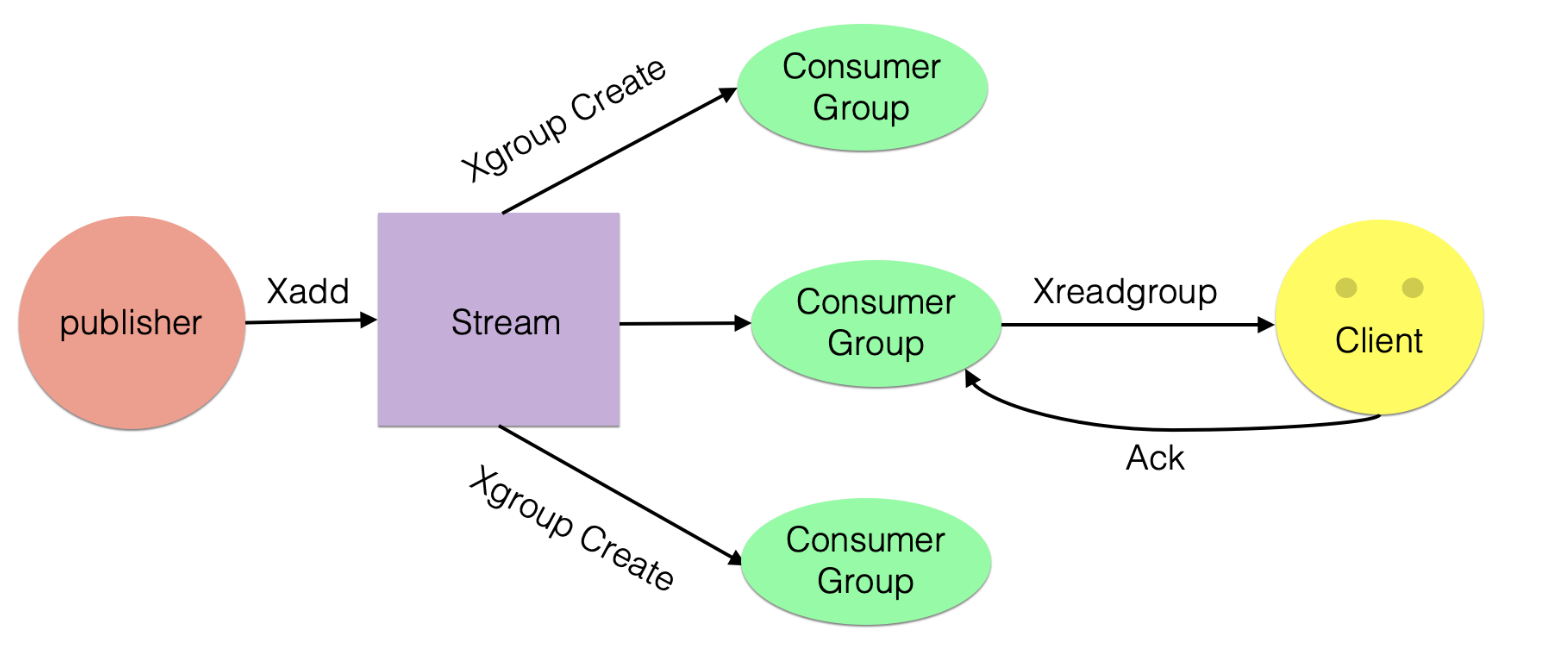
7 Redis Stream用在什么样场景?
可用作时通信等,大数据分析,异地数据备份等
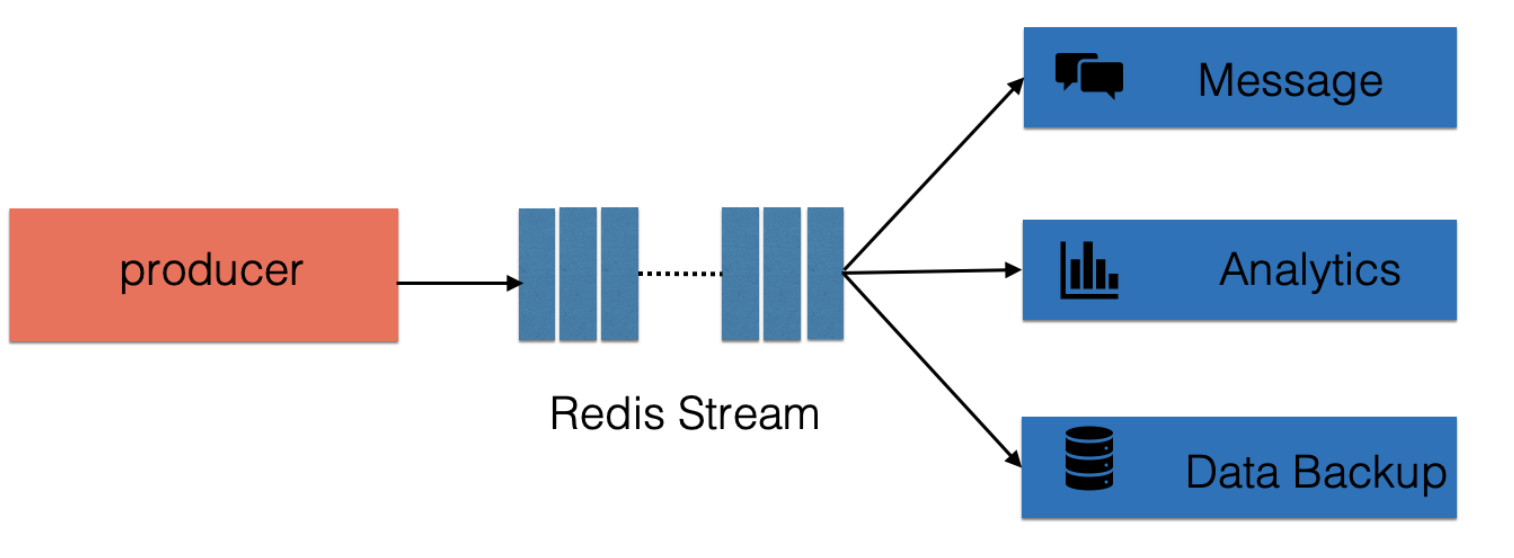
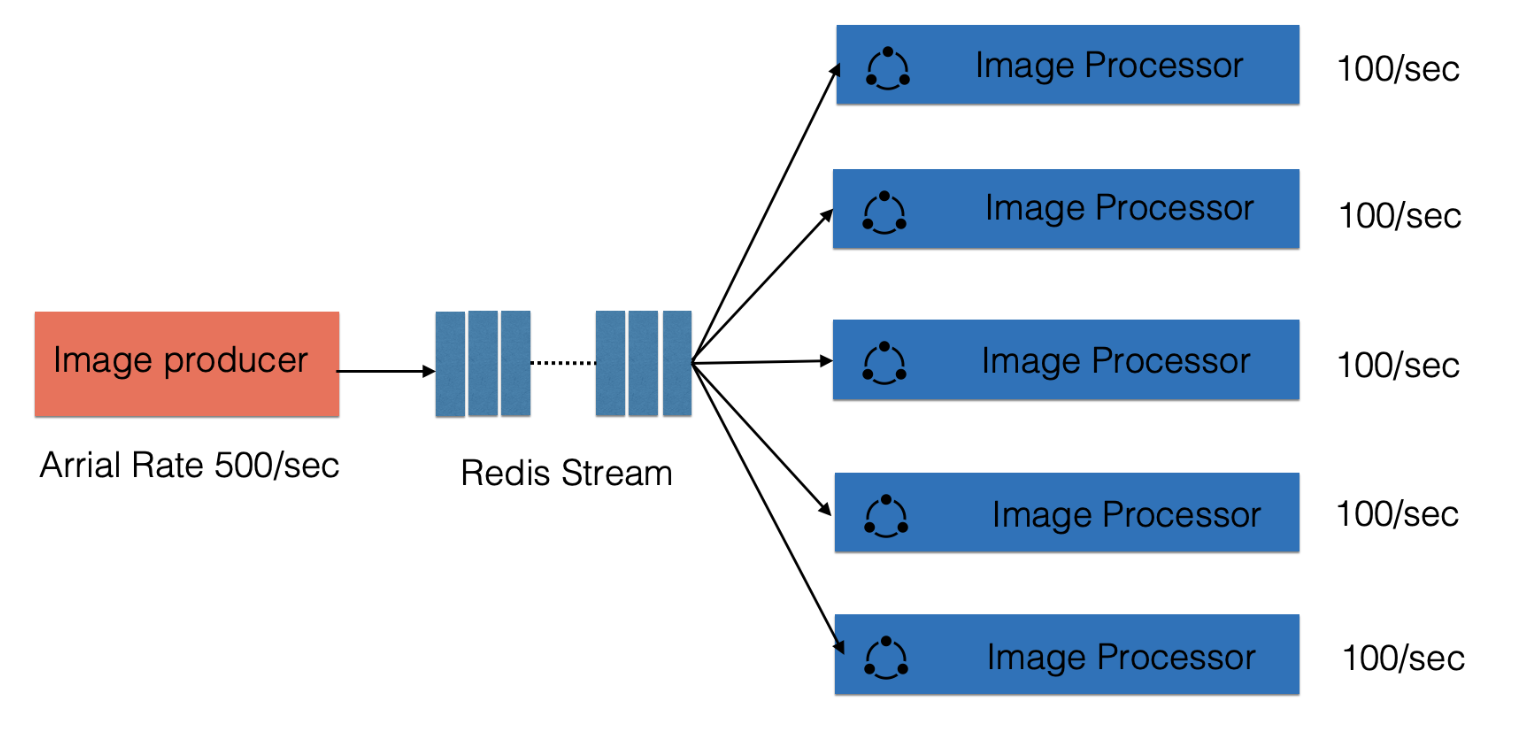
客户端可以平滑扩展,提高处理能力
8 Redis Stream消息ID的设计是否考虑了时间回拨的问题?
XADD生成的1553439850328-0,就是Redis生成的消息ID,由两部分组成:时间戳-序号。时间戳是毫秒级单位,是生成消息的Redis服务器时间,它是个64位整型(int64)。序号是在这个毫秒时间点内的消息序号,它也是个64位整型。
可以通过multi批处理,来验证序号的递增:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> XADD memberMessage * msg one
QUEUED
127.0.0.1:6379> XADD memberMessage * msg two
QUEUED
127.0.0.1:6379> XADD memberMessage * msg three
QUEUED
127.0.0.1:6379> XADD memberMessage * msg four
QUEUED
127.0.0.1:6379> XADD memberMessage * msg five
QUEUED
127.0.0.1:6379> EXEC
1) "1553441006884-0"
2) "1553441006884-1"
3) "1553441006884-2"
4) "1553441006884-3"
5) "1553441006884-4"
由于一个redis命令的执行很快,所以可以看到在同一时间戳内,是通过序号递增来表示消息的。
为了保证消息是有序的,因此Redis生成的ID是单调递增有序的。由于ID中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis的每个Stream类型数据都维护一个latest_generated_id属性,用于记录最后一个消息的ID。若发现当前时间戳退后(小于latest_generated_id所记录的),则采用时间戳不变而序号递增的方案来作为新消息ID(这也是序号为什么使用int64的原因,保证有足够多的的序号),从而保证ID的单调递增性质。
强烈建议使用Redis的方案生成消息ID,因为这种时间戳+序号的单调递增的ID方案,几乎可以满足你全部的需求。但同时,记住ID是支持自定义的,别忘了!
9 Redis Stream消费者崩溃带来的会不会消息丢失问题?
为了解决组内消息读取但处理期间消费者崩溃带来的消息丢失问题,STREAM 设计了 Pending 列表,用于记录读取但并未处理完毕的消息。命令XPENDIING 用来获消费组或消费内消费者的未处理完毕的消息。演示如下:
127.0.0.1:6379> XPENDING mq mqGroup # mpGroup的Pending情况
1) (integer) 5 # 5个已读取但未处理的消息
2) "1553585533795-0" # 起始ID
3) "1553585533795-4" # 结束ID
4) 1) 1) "consumerA" # 消费者A有3个
2) "3"
2) 1) "consumerB" # 消费者B有1个
2) "1"
3) 1) "consumerC" # 消费者C有1个
2) "1"
127.0.0.1:6379> XPENDING mq mqGroup - + 10 # 使用 start end count 选项可以获取详细信息
1) 1) "1553585533795-0" # 消息ID
2) "consumerA" # 消费者
3) (integer) 1654355 # 从读取到现在经历了1654355ms,IDLE
4) (integer) 5 # 消息被读取了5次,delivery counter
2) 1) "1553585533795-1"
2) "consumerA"
3) (integer) 1654355
4) (integer) 4
# 共5个,余下3个省略 ...
127.0.0.1:6379> XPENDING mq mqGroup - + 10 consumerA # 在加上消费者参数,获取具体某个消费者的Pending列表
1) 1) "1553585533795-0"
2) "consumerA"
3) (integer) 1641083
4) (integer) 5
# 共3个,余下2个省略 ...
每个Pending的消息有4个属性:
- 消息ID
- 所属消费者
- IDLE,已读取时长
- delivery counter,消息被读取次数
上面的结果我们可以看到,我们之前读取的消息,都被记录在Pending列表中,说明全部读到的消息都没有处理,仅仅是读取了。那如何表示消费者处理完毕了消息呢?使用命令 XACK 完成告知消息处理完成,演示如下:
127.0.0.1:6379> XACK mq mqGroup 1553585533795-0 # 通知消息处理结束,用消息ID标识
(integer) 1
127.0.0.1:6379> XPENDING mq mqGroup # 再次查看Pending列表
1) (integer) 4 # 已读取但未处理的消息已经变为4个
2) "1553585533795-1"
3) "1553585533795-4"
4) 1) 1) "consumerA" # 消费者A,还有2个消息处理
2) "2"
2) 1) "consumerB"
2) "1"
3) 1) "consumerC"
2) "1"
127.0.0.1:6379>
有了这样一个Pending机制,就意味着在某个消费者读取消息但未处理后,消息是不会丢失的。等待消费者再次上线后,可以读取该Pending列表,就可以继续处理该消息了,保证消息的有序和不丢失。
10 Redis Steam 坏消息问题,死信问题?
正如上面所说,如果某个消息,不能被消费者处理,也就是不能被XACK,这是要长时间处于Pending列表中,即使被反复的转移给各个消费者也是如此。此时该消息的delivery counter就会累加(上一节的例子可以看到),当累加到某个我们预设的临界值时,我们就认为是坏消息(也叫死信,DeadLetter,无法投递的消息),由于有了判定条件,我们将坏消息处理掉即可,删除即可。删除一个消息,使用XDEL语法,演示如下:
# 删除队列中的消息
127.0.0.1:6379> XDEL mq 1553585533795-1
(integer) 1
# 查看队列中再无此消息
127.0.0.1:6379> XRANGE mq - +
1) 1) "1553585533795-0"
2) 1) "msg"
2) "1"
2) 1) "1553585533795-2"
2) 1) "msg"
2) "3"
注意本例中,并没有删除Pending中的消息因此你查看Pending,消息还会在。可以执行XACK标识其处理完毕!