Redis集群:hash寻址算法
Redis集群:hash寻址算法
1. 普通hash
普通hash也就是最简单的hash算法,即
index = hash(key) % N
index表示机器的索引,N表示机器的数量,假设有三台机器,即N=3,那么普通hash结果如下图,很简单是吧
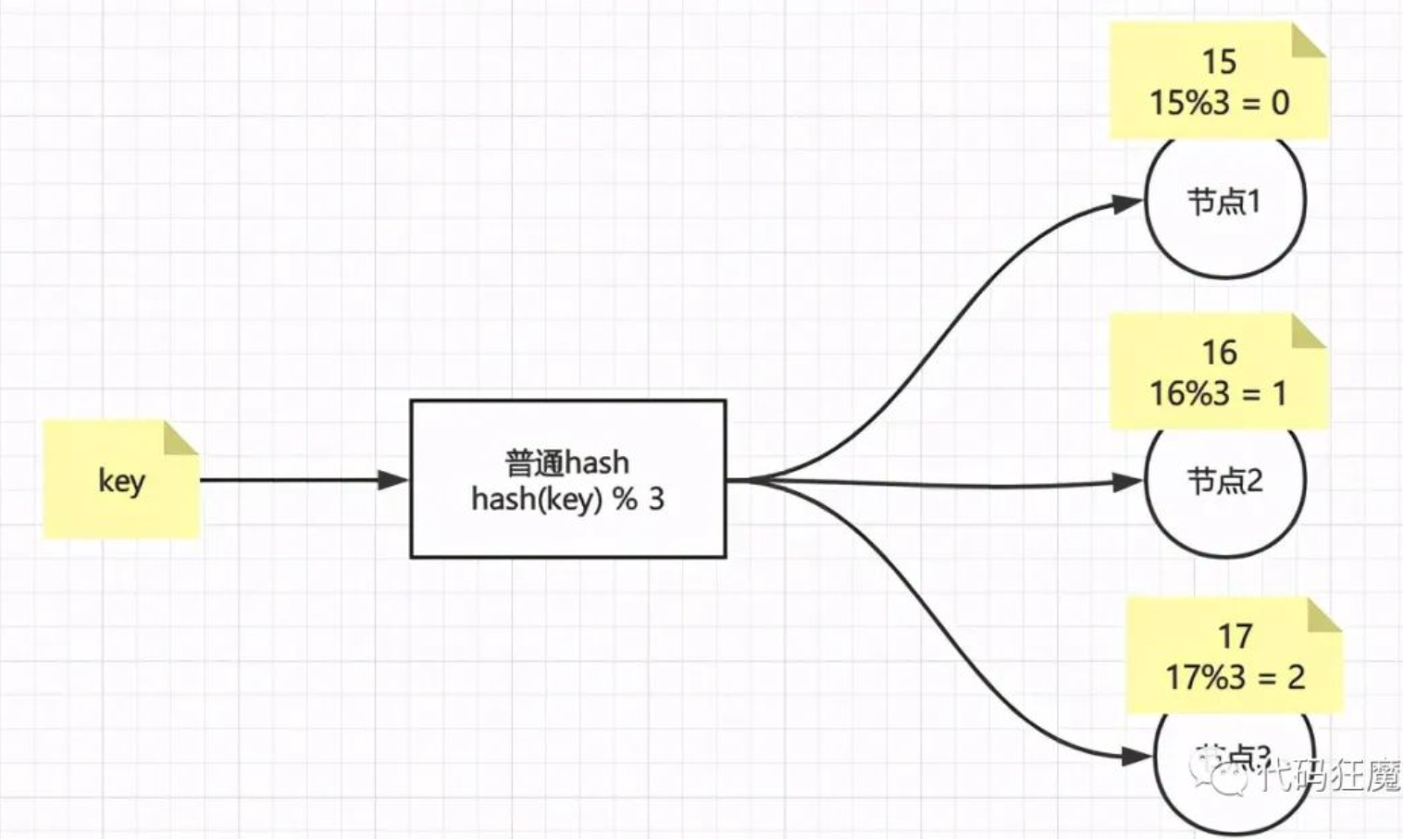
那如果现在增加了一台机器呢?
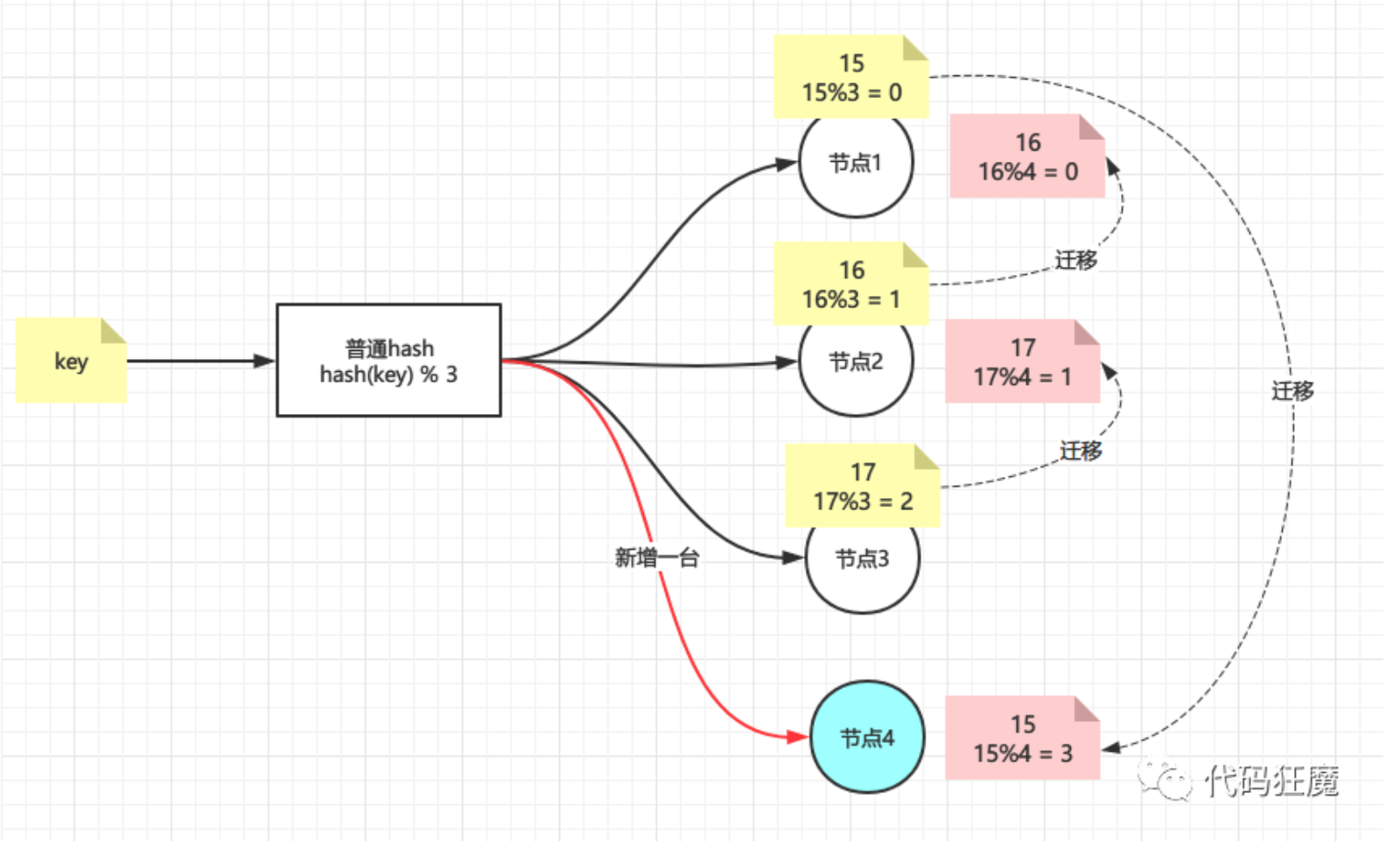
情况似乎变得复杂起来,因为新增加了一个节点4,即N=4,那么所有key取模的结果都变了,导致所有的数据都要重新迁移一遍,如果节点4下线了呢?那么毫无疑问所有数据都要还原回去,就redis而言,这就叫大量缓存的重建,那么有没有新增/删除节点影响不那么大的hash算法呢?答案肯定是有,下面轮到一致性hash出场。
2. 一致性hash
一致哈希由MIT的Karger及其合作者提出,现在这一思想已经扩展到其它领域。在这篇1997年发表的学术论文中介绍了“一致哈希”如何应用于用户易变的分布式Web服务中。哈希表中的每一个代表分布式系统中一个节点,在系统添加或删除节点只需要移动K/n (方法K是总key的个数,n是节点个数)
一致性hash的特性
- 平衡性:尽可能让数据尽可能分散到所有节点上,避免造成极其不均匀
- 单调性:要求在新增或者减少节点的时候,原有的结果绝大部分不受影响,而新增的数据尽可能分配到新加的节点
- 分散性:好的算法在不同终端,针对相同的数据的计算,得到的结果应该是一样的,一致性要很强
- 负载:针对相同的节点,避免被不同终端映射不同的内容
- 平滑性:对于增加节点或者减少节点,应该能够平滑过渡
2.1 hash环
普通hash算法导致大量数据迁移的根本原因是N的不确定性,有没有在N变化的时候影响范围更小的算法呢?有人提出了环的概念
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用
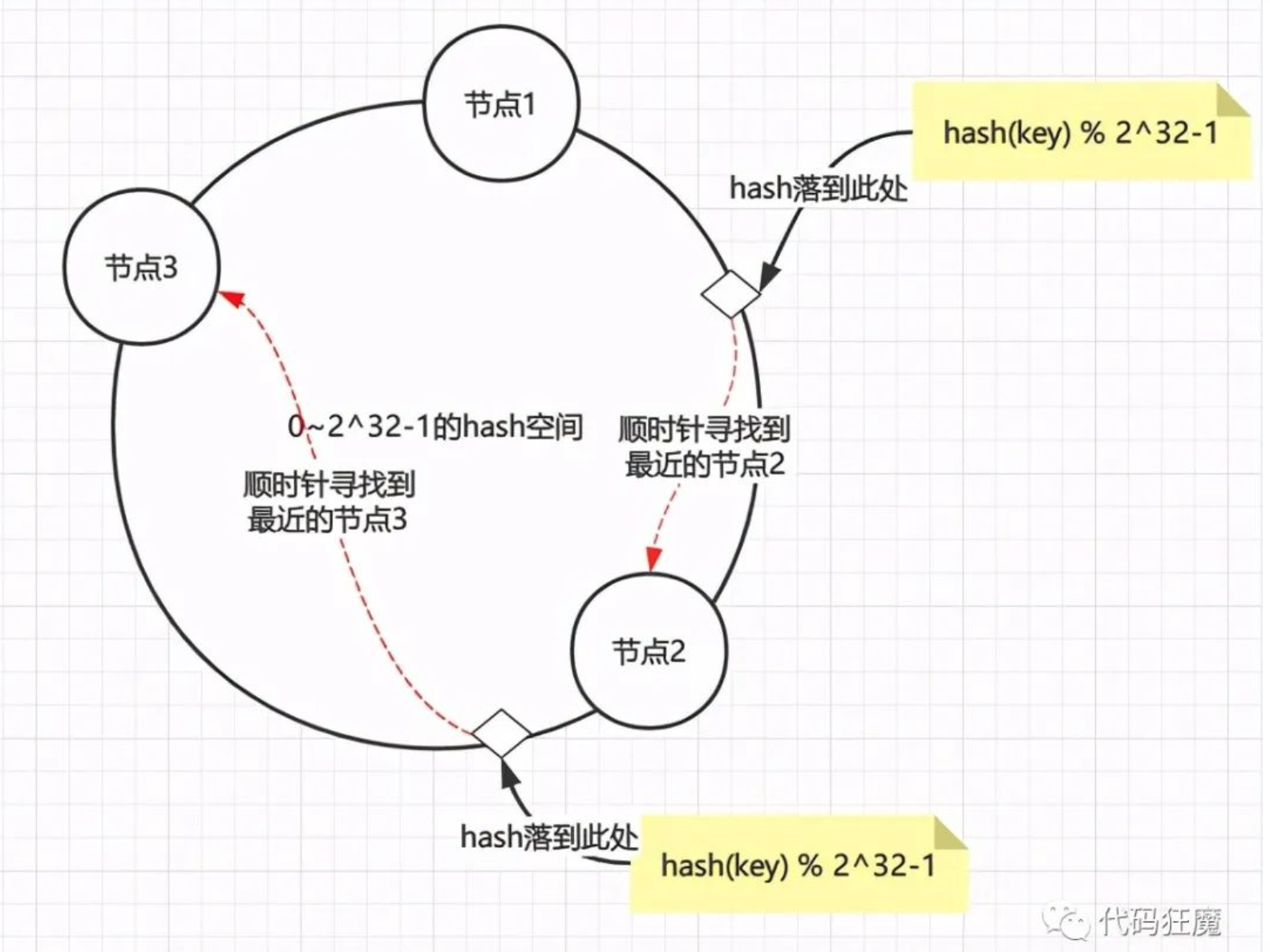
hash环通过构建环状的hash空间代替线性hash空间的方法解决了上面的问题,假设将0~2^32-1的hash空间分布到一个环上
- 节点加入环:将节点通过hash(节点的信息如ip端口等) % 2^32-1取节点在环上位置
- 数据读写:读写数据时同样取key的hash,即hash(key) % 2^32-1落到环上的某一位置,再顺时针找到离环最近的那个节点进行读写
整个过程如下图
假设现在新增一个节点4,只会影响到节点2到节点4之间的数据,其他的数据不会被影响到,这也是一致性的体现
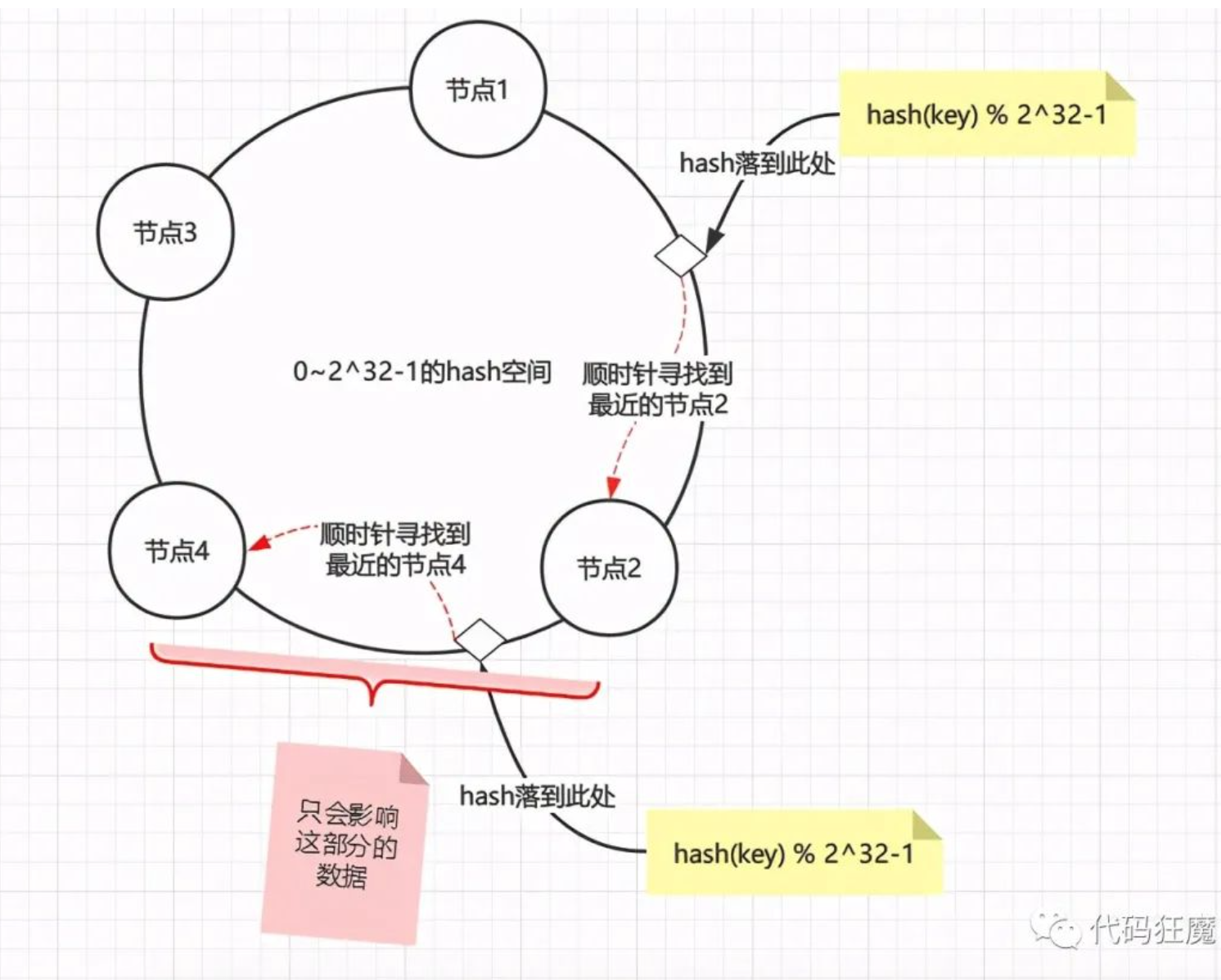
删除一个节点也是同样的道理,假设删除节点4,也只是会影响到节点2到原节点4之间的数据,总之不管新增还是删除线路都只会影响到变动节点到变动节点逆时针找到的最近一个节点的数据。
当然hash环也不是没有问题的,假设节点分布不均匀(hash算法并不能保证绝对的平衡性),那么大部分数据都会落在一个节点上,导致请求和数据倾斜,这样就不能很好的保证负载均衡。
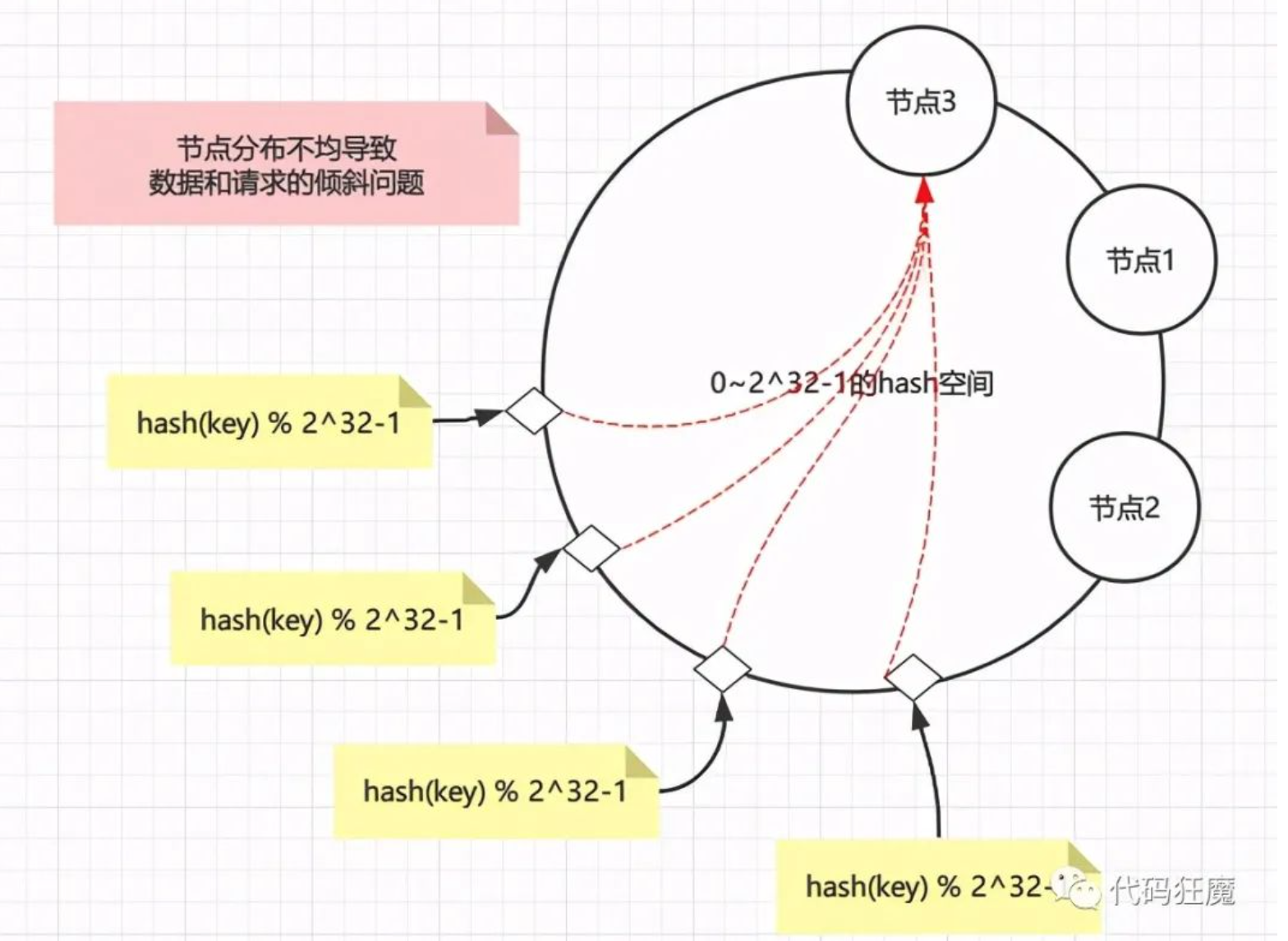
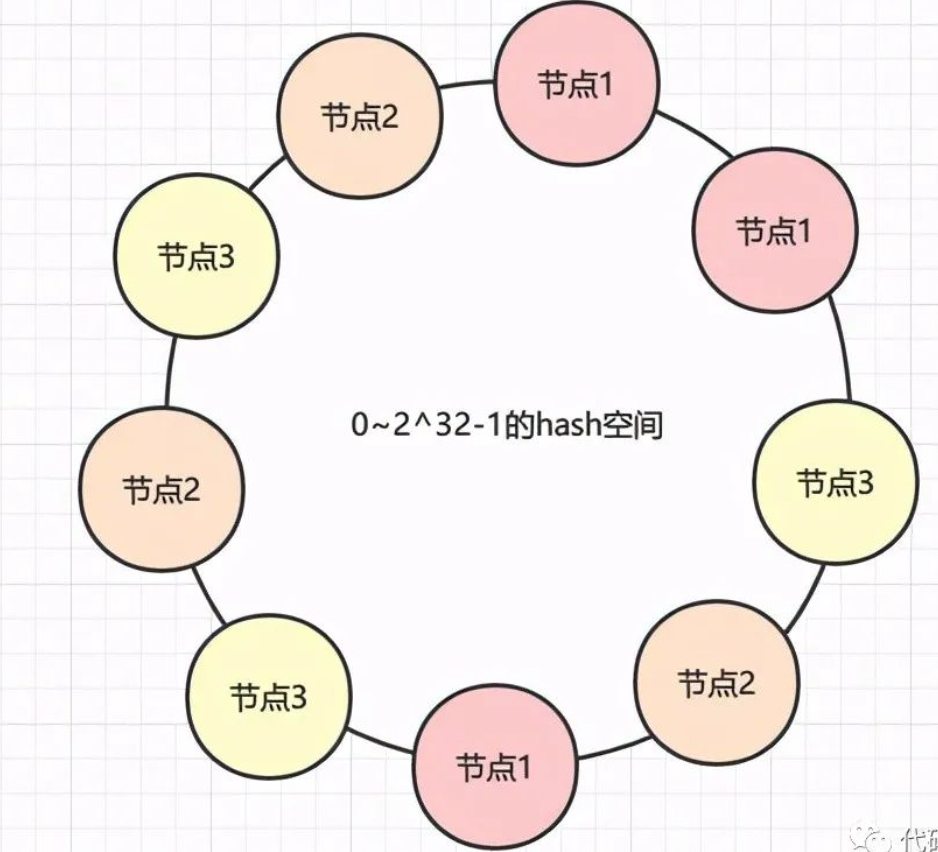
那么解决办法就是增加虚拟节点(注意,此时环上全部都是虚拟节点),对每一个节点计算多个hash,尽量保证环上的节点是均匀的,如下图
3. hash槽
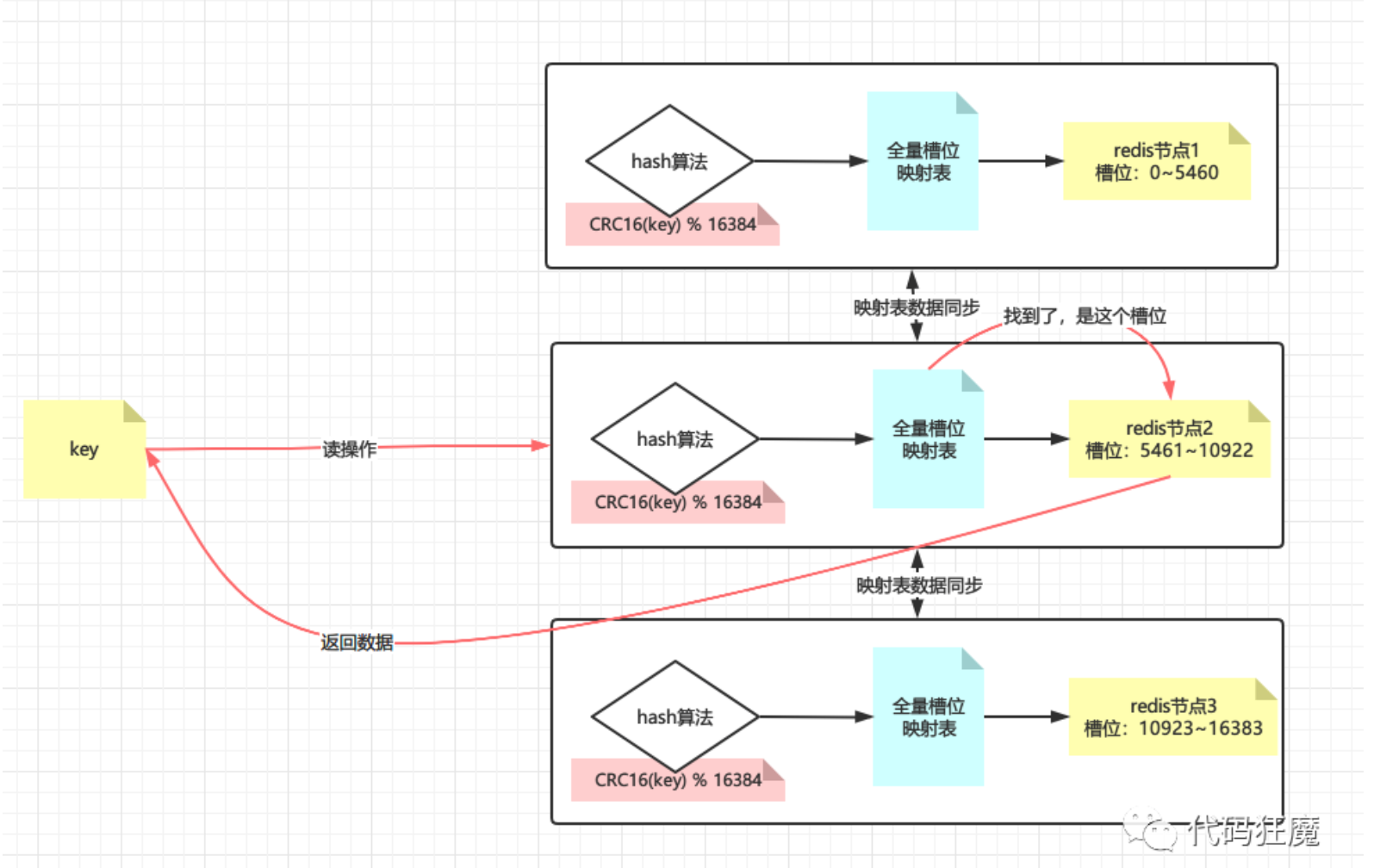
redis默认分配16384个hash槽位,然后将槽位均匀分配到不同的redis实例中去,找数据的时候通过CRC16算法计算后再取模找到对应的槽位(CRC16我们应该不陌生,这个winrar里面使用的CRC32是一样的,只是校验长度不一样而已),算法如下
CRC16(key) % 16384
再看槽位在哪台实例上,最后去实例上取数据,如下图所示
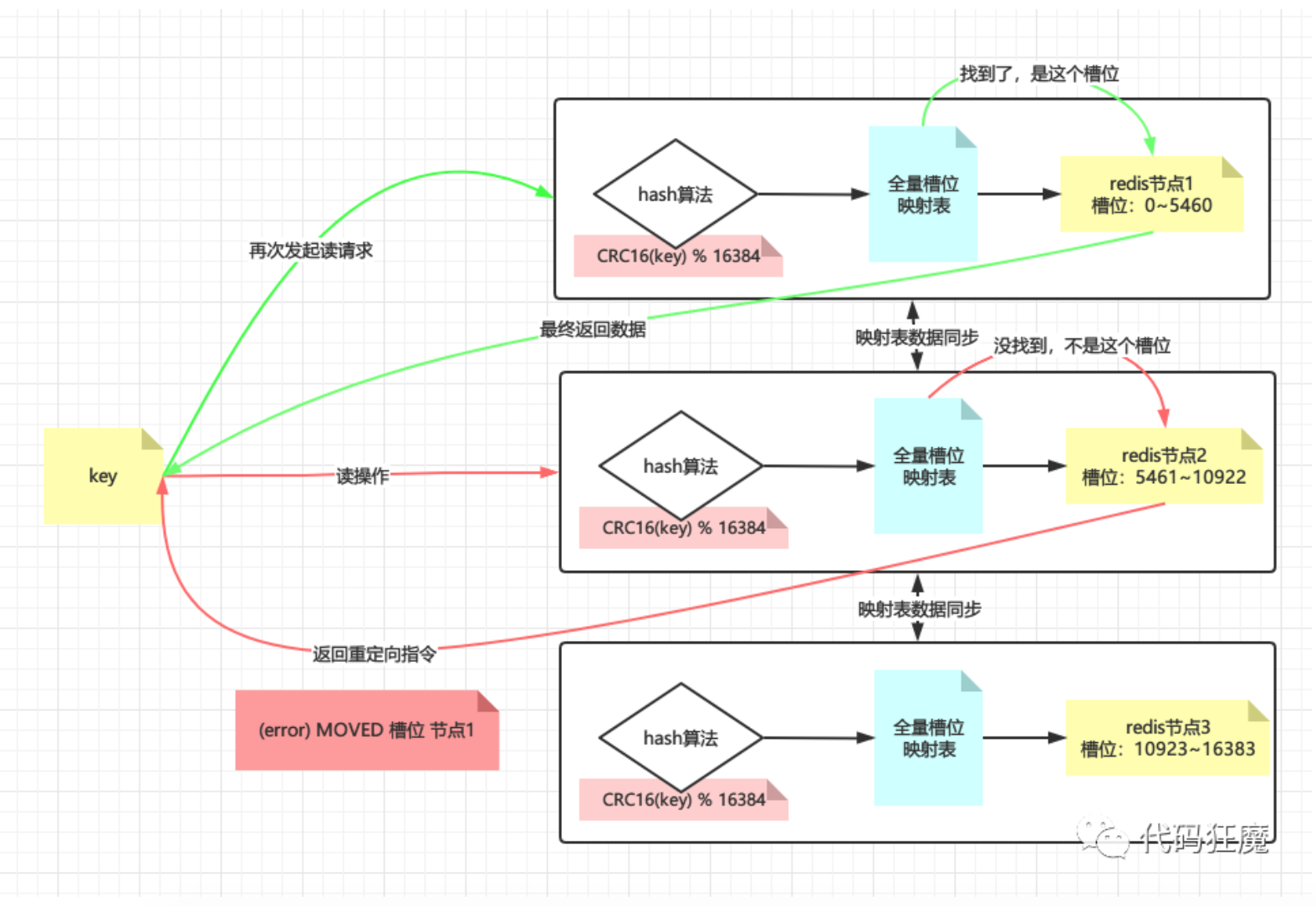
如果该槽位不在请求的实例上呢?此时该实例会返回重定向指令:MOVED 槽位 目标实例,能这么做的基础是每一台redis实例上都有全量的hash槽的映射表,如下图所示为重定向的例子
使用槽位将具体的数据与redis实例解耦,当新增或者减少redis实例的时候用redis cluster总线通过Ping/Pong报文进行广播,告知整个redis集群新节点上线/下线,并迁移槽位和更新集群中的槽位映射表,整个过程尽量保证hash槽的平均分布
3.1 那么是基于什么样的考虑,redis的作者没有用hash环呢?
redis的作者认为他的CRC16(key) mod 16384的效果已经不错了,虽然没有一致性hash灵活,但实现很简单,节点增删时处理起来也很方便
当然还有个原因是hash槽的分布更加均匀,如果有N个节点,那么每个节点都负载1/N,