redis大数据查询还不如直接查数据库
2022年12月24日约 638 字大约 2 分钟
redis大数据查询还不如直接查数据库
1. 背景
我们字典表数据会根据 字典名 存redis 作为缓存使用,但是字典并不单单有我们系统中新增的。还包括国标 的字典表。如 民族代码,职业代码,行政区划代码。这些国标字典表是单独存表的(我们以T_开头)
为了保持逻辑一致,我们在service 层通过表前缀 T_ 区分是系统字典表还是 国标字典表。转成统一的数据结构返回。其中会将字典表的数据存储在redis 中
2. 问题
在一次系统测试过程中发现业务接口响应时间长。排查发现是redis 查询 全国行政区划代码 慢,
- redis查询
全国行政区划代码花费:200ms - 直接查询数据库 花费10ms
3. 排查定位
3.1 redis 慢日志
通过查询慢日志定位redis 中哪些key 操作的慢
SLOWLOG get 10
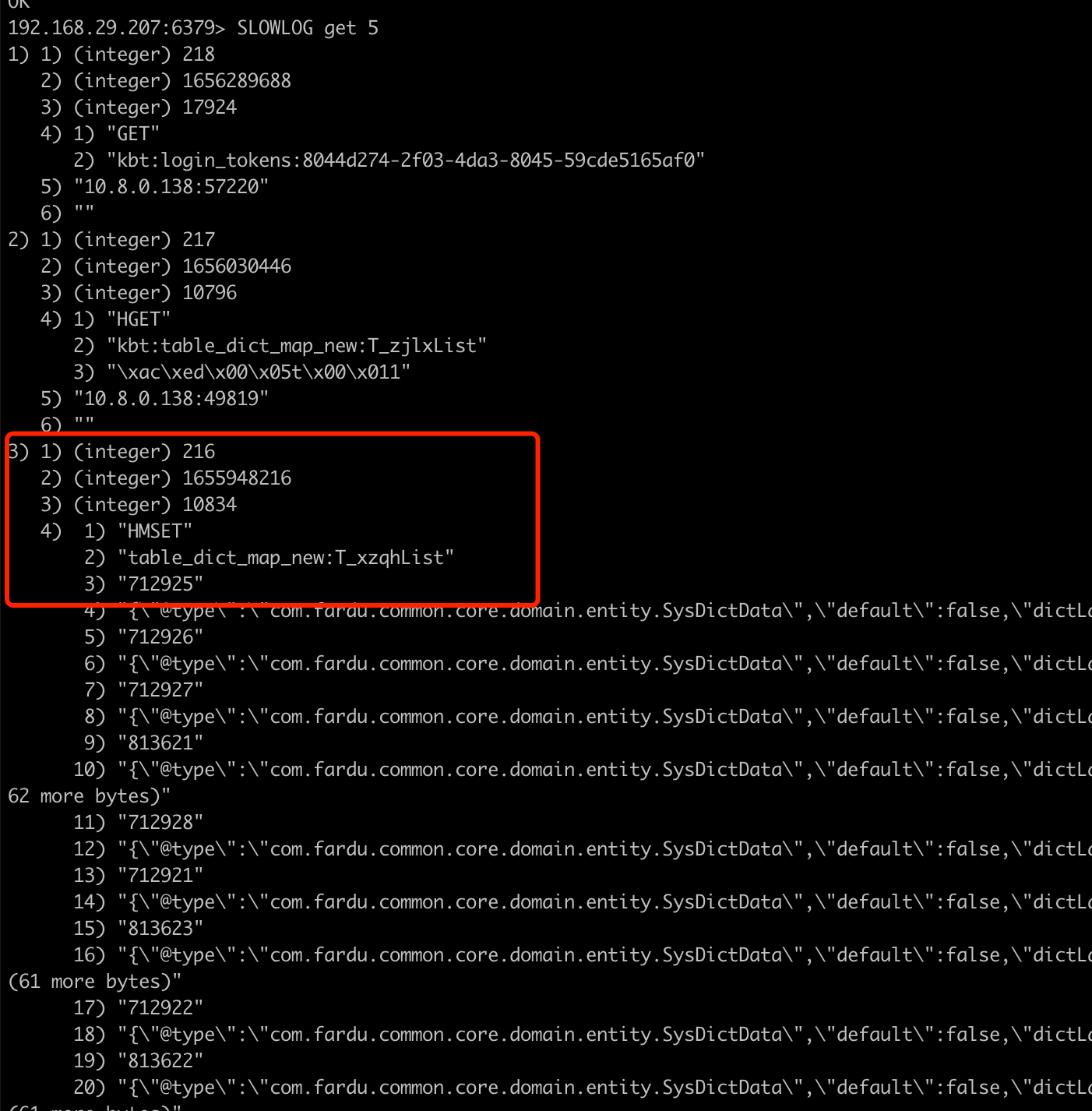
我们可以看到行政区划代码redis 中查询花费了10ms,再加上网络传输和数据格式组装就更久了
3.2 redis 查询bigkeys
查询bigkeys 信息
redis-cli -h 192.168.0.1 -p 6379 -a "xxxx" --bigkeys
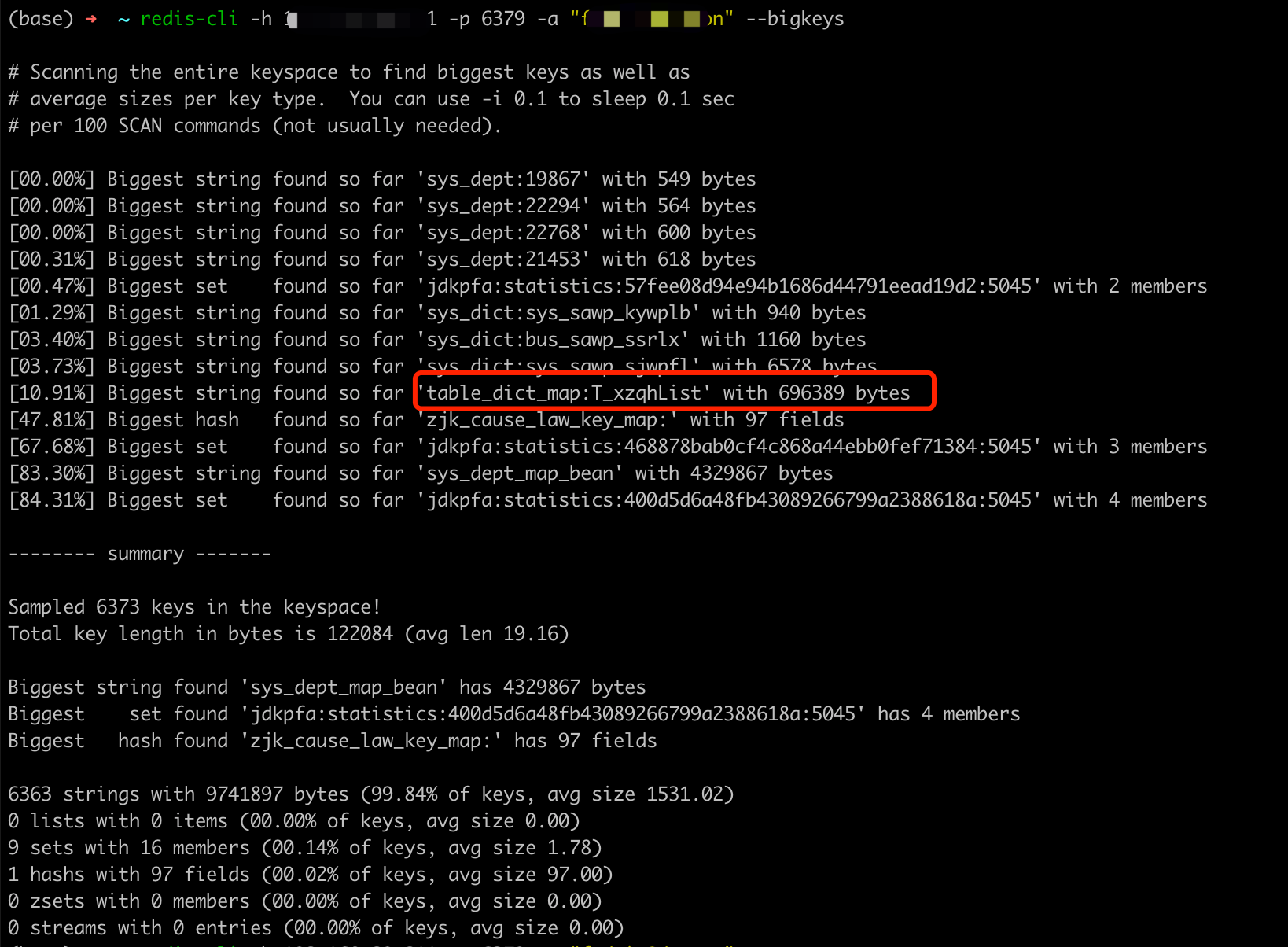
我们可以看到行政区划就占了0.6M 大小。已经非常大了
4. 解决方案
根据实际业务需求,行政区划代码其实基本不变,我们可以将他放在前端或者服务端内存中做一级缓存就可以了。(ps:redis 属于二级缓存)
5. 大bigkeys 怎么办
这里有两点可以优化:
- 业务应用尽量避免写入 bigkey
- 如果你使用的 Redis 是 4.0 以上版本,用 UNLINK 命令替代 DEL,此命令可以把释放 key 内存的操作,放到后台线程中去执行,从而降低对 Redis 的影响
- 如果你使用的 Redis 是 6.0 以上版本,可以开启 lazy-free 机制(lazyfree-lazy-user-del = yes),在执行 DEL 命令时,释放内存也会放到后台线程中执行
但即便可以使用方案 2,我也不建议你在实例中存入 bigkey。
这是因为 bigkey 在很多场景下,依旧会产生性能问题。例如,bigkey 在分片集群模式下,对于数据的迁移也会有性能影响,以及我后面即将讲到的数据过期、数据淘汰、透明大页,都会受到 bigkey 的影响。
Powered by Waline v2.9.1