线上OOM-记一次OOM排查过程
线上OOM-记一次OOM排查过程
1. 背景
项目中有个需求是将爬虫爬取到的网页数据(存放在mongodb), 做数据清理后放入搜索引擎(solr)中。总共350w的网页数据,如果按正常速度同步10个小时即可完成。但我们实际测试发现,随着时间推移,同步时间越来越长,挂了一天只同步了100w数据。且后面越来越慢。领导找到我,让我帮忙排查解决
2. 解决一: mongodb 大数据量分页查询效率问题
通过查阅资料了解到
虽然MongoDB提供了skip()和limit()方法。看起来,分页已经实现了,但是官方文档并不推荐,说会扫描全部文档,然后再返回结果。
The cursor.skip() method requires the server to scan from the beginning of the input results set before beginning to return results. As the offset increases, cursor.skip() will become slower.
cursor.skip() 方法要求服务器先从输入结果集开始扫描,然后再开始返回结果。随着偏移量的增加,cursor.skip() 会变慢。
所以,需要一种更快的方式。其实和mysql数量大之后不推荐用limit m,n一样,解决方案是先查出当前页的第一条,然后顺序数pageSize条。MongoDB官方也是这样推荐的。
2.1 解决方案1:通过_id 比较取分页
我们假设基于_id的条件进行查询比较。事实上,这个比较的基准字段可以是任何你想要的有序的字段,比如时间戳。
//Page 1
db.users.find().limit(pageSize);
//Find the id of the last document in this page
last_id = ...
//Page 2
users = db.users.find({
'_id' :{ "$gt" :ObjectId("5b16c194666cd10add402c87")}
}).limit(10)
//Update the last id with the id of the last document in this page
last_id = ...
显然,第一页和后面的不同。对于构建分页API, 我们可以要求用户必须传递pageSize, lastId。
- pageSize 页面大小
- lastId 上一页的最后一条记录的id,如果不传,则将强制为第一页
2.2 解决方案2:通过游标来查询
FindIterable<Document> findIterable = mongoTemplate.getCollection(mongoTemplate.getCollectionName(tClass))
.find()
.noCursorTimeout(true)
.batchSize(1000);
MongoCursor<Document> cursor = findIterable.cursor();
while (cursor.hasNext()){
}
2.3 优化成果
最终我采用游标的方式来查询,在做数据清理的时候,非常稳定,不会随着深度增加而越来越慢,花费9小时左右完成同步
3. OOM引发:通过多线程来优化
花费9个小时还是太久了,大部分时间都浪费在数据清理和上传到solr 上。我们希望通过多线程来优化
但改成多线程版本后发现OOM 了
3.1 OOM: GC overhead limit exceeded
我们知道 OOM: GC overhead limit exceeded ,意味着超过98%的时间用来做GC并且回收了不到2%的堆内存
并行/并发回收器在GC回收时间过长时会抛出OutOfMemroyError。过长的定义是,超过98%的时间用来做GC并且回收了不到2%的堆内存。用来避免内存过小造成应用不能正常工作。
我们查看gc日志分析,后期gc特别频繁
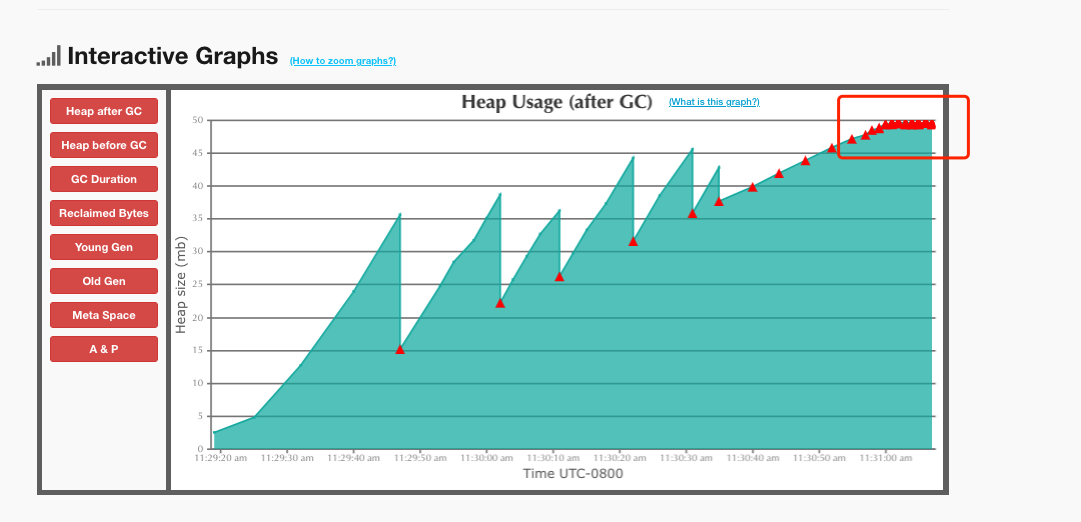
3.2 查看 GC-Roots 引用链
我们知道OOM 堆内存溢出,主要因为 Java 堆中不断的创建对象,并且 GC-Roots 到对象之间存在引用链,这样 JVM 就不会回收对象。才导致内存溢出
我们查看 GC-Roots 引用链 ,查看对象和 GC-Roots 是如何进行关联的,是否存在对象的生命周期过长等问题
我们使用JProfiler 可以看到 堆中存在大量我们爬取的网页内容,并且远超的我们的堆内存范围
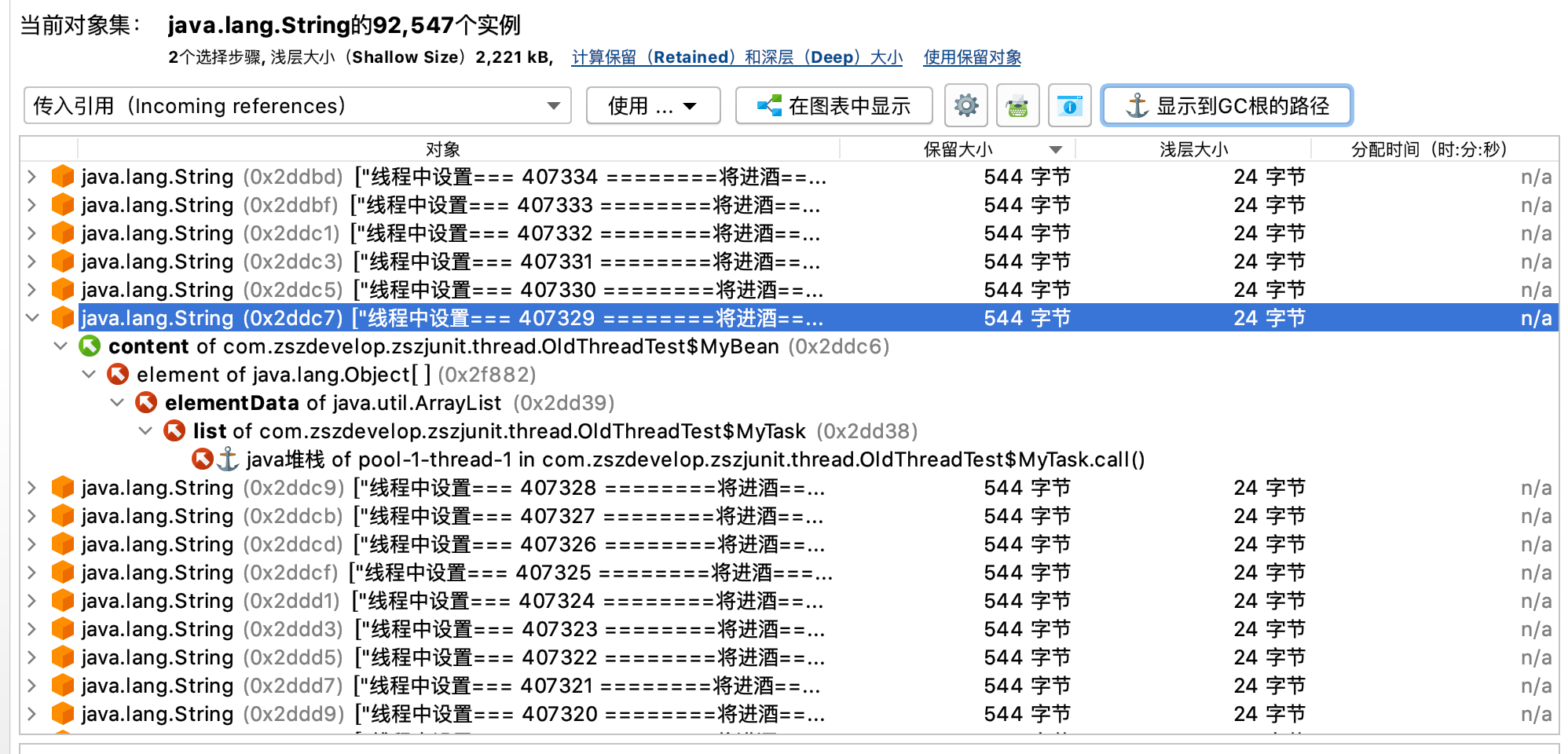
3.3 分析我们的代码,查找原因
通过gcroot 我们已经知道是的对象无法回收。
我们350w的网页内容直接放到堆中处理,肯定会存在OOM。但我们使用了线程池,线程池中带有阻塞队列,按理应该会阻塞才对。消费完才能再生产,现在不生效肯定是线程池的问题
通过排查发现,我们用spring bean 引的全局线程池,他的阻塞队列并没有设置拒绝策略,采用了默认的拒绝策略
// 构建一个10核心线程,20最大线程,最大队列为1000
ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 20, 200, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(1000));
默认的拒绝策略是ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常
我们加上了拒绝策略,ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务 。
ps: 加了CallerRunsPolicy 阻塞队列才能发挥阻塞作用。
3.4 优化成功
我们加入拒绝策略后,阻塞队列产生了效果。产生和消费处于平衡状态,生产一批,消费一批。内存稳定。最终花费3小时完成了数据清理工作