分布式系统-分布式锁
分布式系统-分布式锁
1. 什么是分布式锁
要介绍分布式锁,首先要提到与分布式锁相对应的是线程锁、进程锁。
- 线程锁:主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如synchronized是共享对象头,显示锁Lock是共享某个变量(state)。
- 进程锁:为了控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过synchronized等线程锁实现进程锁。
- 分布式锁:当多个进程不在同一个系统中(比如分布式系统中控制共享资源访问),用分布式锁控制多个进程对资源的访问。
2. 分布式锁的设计原则
分布式锁的最小设计原则:安全性和有效性
Redis的官网上对使用分布式锁提出至少需要满足如下三个要求:
- 互斥(属于安全性):在任何给定时刻,只有一个客户端可以持有锁。
- 无死锁(属于有效性):即使锁定资源的客户端崩溃或被分区,也总是可以获得锁;通常通过超时机制实现。
- 容错性(属于有效性):只要大多数 Redis 节点都启动,客户端就可以获取和释放锁。
除此之外,分布式锁的设计中还可以/需要考虑:
- 加锁解锁的同源性:A加的锁,不能被B解锁
- 获取锁是非阻塞的:如果获取不到锁,不能无限期等待;
- 高性能:加锁解锁是高性能的
3. 基于数据库如何实现分布式锁?有什么缺陷?
基于数据库如何实现分布式锁?有什么缺陷?
3.1 基于数据库表(锁表,很少使用)
最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。当我们想要获得锁的时候,就可以在该表中增加一条记录,想要释放锁的时候就删除这条记录。
为了更好的演示,我们先创建一张数据库表,参考如下:
CREATE TABLE database_lock (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`resource` int NOT NULL COMMENT '锁定的资源',
`description` varchar(1024) NOT NULL DEFAULT "" COMMENT '描述',
PRIMARY KEY (id),
UNIQUE KEY uiq_idx_resource (resource)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='数据库分布式锁表';
当我们想要获得锁时,可以插入一条数据:
INSERT INTO database_lock(resource, description) VALUES (1, 'lock');
当需要释放锁的时,可以删除这条数据:
DELETE FROM database_lock WHERE resource=1;
3.2 基于悲观锁
3.2.1 悲观锁实现思路?
- 在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)。
- 如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。 具体响应方式由开发者根据实际需要决定。
- 如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
- 其间如果有其他对该记录做修改或加排他锁的操作,都会等待我们解锁或直接抛出异常。
3.2.2 以MySQL InnoDB中使用悲观锁为例?
要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。set autocommit=0;
//0.开始事务
begin;/begin work;/start transaction; (三者选一就可以)
//1.查询出商品信息
select status from t_goods where id=1 for update;
//2.根据商品信息生成订单
insert into t_orders (id,goods_id) values (null,1);
//3.修改商品status为2
update t_goods set status=2;
//4.提交事务
commit;/commit work;
上面的查询语句中,我们使用了select…for update的方式,这样就通过开启排他锁的方式实现了悲观锁。此时在t_goods表中,id为1的 那条数据就被我们锁定了,其它的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。
上面我们提到,使用select…for update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL InnoDB默认行级锁。行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住,这点需要注意。
3.3 基于乐观锁
乐观并发控制(又名“乐观锁”,Optimistic Concurrency Control,缩写“OCC”)是一种并发控制的方法。它假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
3.3.1 以使用版本号实现乐观锁为例?
使用版本号时,可以在数据初始化时指定一个版本号,每次对数据的更新操作都对版本号执行+1操作。并判断当前版本号是不是该数据的最新的版本号。
1.查询出商品信息
select (status,status,version) from t_goods where id=#{id}
2.根据商品信息生成订单
3.修改商品status为2
update t_goods
set status=2,version=version+1
where id=#{id} and version=#{version};
需要注意的是,乐观锁机制往往基于系统中数据存储逻辑,因此也具备一定的局限性。由于乐观锁机制是在我们的系统中实现的,对于来自外部系统的用户数据更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。在系统设计阶段,我们应该充分考虑到这些情况,并进行相应的调整(如将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途径,而不是将数据库表直接对外公开)。
3.4 缺陷
- 对数据库依赖
- 开销问题
- 行锁变表锁问题
- 无法解决数据库单点和可重入的问题。
4. 基于redis如何实现分布式锁?有什么缺陷?
基于redis如何实现分布式锁?这里一定要看Redis的官网 (opens new window)的分布式锁的实现这篇文章。
4.1 set NX PX + Lua
加锁: set NX PX + 重试 + 重试间隔
向Redis发起如下命令: SET productId:lock 0xx9p03001 NX PX 30000 其中,"productId"由自己定义,可以是与本次业务有关的id,"0xx9p03001"是一串随机值,必须保证全局唯一(原因在后文中会提到),“NX"指的是当且仅当key(也就是案例中的"productId:lock”)在Redis中不存在时,返回执行成功,否则执行失败。"PX 30000"指的是在30秒后,key将被自动删除。执行命令后返回成功,表明服务成功的获得了锁。
@Override
public boolean lock(String key, long expire, int retryTimes, long retryDuration) {
// use JedisCommands instead of setIfAbsense
boolean result = setRedis(key, expire);
// retry if needed
while ((!result) && retryTimes-- > 0) {
try {
log.debug("lock failed, retrying..." + retryTimes);
Thread.sleep(retryDuration);
} catch (Exception e) {
return false;
}
// use JedisCommands instead of setIfAbsense
result = setRedis(key, expire);
}
return result;
}
private boolean setRedis(String key, long expire) {
try {
RedisCallback<String> redisCallback = connection -> {
JedisCommands commands = (JedisCommands) connection.getNativeConnection();
String uuid = SnowIDUtil.uniqueStr();
lockFlag.set(uuid);
return commands.set(key, uuid, NX, PX, expire); // 看这里
};
String result = redisTemplate.execute(redisCallback);
return !StringUtil.isEmpty(result);
} catch (Exception e) {
log.error("set redis occurred an exception", e);
}
return false;
}
解锁:采用lua脚本
在删除key之前,一定要判断服务A持有的value与Redis内存储的value是否一致。如果贸然使用服务A持有的key来删除锁,则会误将服务B的锁释放掉。
if redis.call("get", KEYS[1])==ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
4.2 基于RedLock实现分布式锁
这是Redis作者推荐的分布式集群情况下的方式,请看这篇文章Is Redlock safe?
假设有两个服务A、B都希望获得锁,有一个包含了5个redis master的Redis Cluster,执行过程大致如下:
- 客户端获取当前时间戳,单位: 毫秒
- 服务A轮寻每个master节点,尝试创建锁。(这里锁的过期时间比较短,一般就几十毫秒) RedLock算法会尝试在大多数节点上分别创建锁,假如节点总数为n,那么大多数节点指的是n/2+1。
- 客户端计算成功建立完锁的时间,如果建锁时间小于超时时间,就可以判定锁创建成功。如果锁创建失败,则依次(遍历master节点)删除锁。
- 只要有其它服务创建过分布式锁,那么当前服务就必须轮寻尝试获取锁。
4.3 基于Redis的客户端
这里Redis的客户端(Jedis, Redisson, Lettuce等)都是基于上述两类形式来实现分布式锁的,只是两类形式的封装以及一些优化(比如Redisson的watch dog)。
以基于Redisson实现分布式锁为例(支持了 单实例、Redis哨兵、redis cluster、redis master-slave等各种部署架构):
4.3.1 特色?
- redisson所有指令都通过lua脚本执行,保证了操作的原子性
- redisson设置了watchdog看门狗,“看门狗”的逻辑保证了没有死锁发生
- redisson支持Redlock的实现方式。
4.3.2 过程?
- 线程去获取锁,获取成功: 执行lua脚本,保存数据到redis数据库。
- 线程去获取锁,获取失败: 订阅了解锁消息,然后再尝试获取锁,获取成功后,执行lua脚本,保存数据到redis数据库。
4.3.3 互斥?
如果这个时候客户端B来尝试加锁,执行了同样的一段lua脚本。第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在。接着第二个if判断,判断myLock锁key的hash数据结构中,是否包含客户端B的ID,但明显没有,那么客户端B会获取到pttl myLock返回的一个数字,代表myLock这个锁key的剩余生存时间。此时客户端B会进入一个while循环,不听的尝试加锁。
4.3.4 watch dog自动延时机制?
客户端A加锁的锁key默认生存时间只有30秒,如果超过了30秒,客户端A还想一直持有这把锁,怎么办?其实只要客户端A一旦加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果客户端A还持有锁key,那么就会不断的延长锁key的生存时间。
4.3.5 可重入?
每次lock会调用incrby,每次unlock会减一。
4.4 进一步理解
- 借助Redis实现分布式锁时,有一个共同的缺陷: 当获取锁被拒绝后,需要不断的循环,重新发送获取锁(创建key)的请求,直到请求成功。这就造成空转,浪费宝贵的CPU资源。
- RedLock算法本身有争议,具体看这篇文章How to do distributed locking (opens new window) 以及作者的回复Is Redlock safe?
5. 基于zookeeper如何实现分布式锁?
说几个核心点:
- 顺序节点
创建一个用于发号的节点“/test/lock”,然后以它为父亲节点的前缀为“/test/lock/seq-”依次发号:
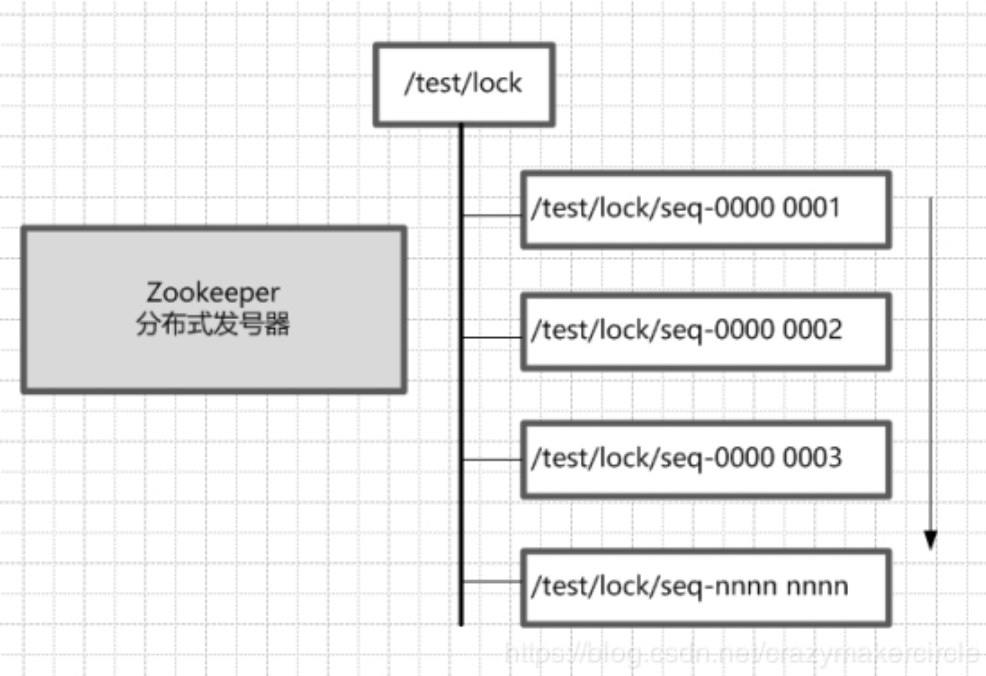
获得最小号得锁
由于序号的递增性,可以规定排号最小的那个获得锁。所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
节点监听机制
每个线程抢占锁之前,先抢号创建自己的ZNode。同样,释放锁的时候,就需要删除抢号的Znode。抢号成功后,如果不是排号最小的节点,就处于等待通知的状态。等谁的通知呢?不需要其他人,只需要等前一个Znode 的通知就可以了。当前一个Znode 删除的时候,就是轮到了自己占有锁的时候。第一个通知第二个、第二个通知第三个,击鼓传花似的依次向后。